이 글은 <핸즈온 머신러닝 2판>에 의해 만들어졌습니다.
2. 케라스로 다층 퍼셉트론 구현하기
케라스는 모든 종류의 신경망을 손쉽게 만들고 훈련, 평가, 실행할 수 있는 고수준 딥러닝 API입니다.
API 문서(또는 명세) : http://keras.io
케라스의 참조 구현은 2015년 3월에 오픈소스로 공개되었습니다. (다양한 유연성과 아름다운 디자인)
이 참조 구현은 계산 백엔드(backend)에 의존하여 신경망에 필요한 많은 연산을 수행합니다.
인기 있는 3가지 딥러닝 라이브러리 중에서 백엔드를 선택이 가능합니다.
- 텐서플로
- 마이크로소프트 코그니티브 툴킷(Microsoft Cognitive Toolkit)(CNTK)
- 시애노
2016년 후반부터 다른 구현이 릴리스되기 시작했습니다.
지금은 아파치(Apache) MXNet, 애플의 Core ML, (웹 브라우저에서 케라스 코드를 실행하려면) 자바스크립트나 타입스크립트, (엔비디아(Nvidia)뿐만 아니라 모든 종류의 GPU 장치에서 실행할 수 있는) PlaidML에서 케라스를 실행할 수 있습니다.
또한 텐서플로는 자체적인 케라스 구현인 tf.keras를 번들로 포함시킴. (백엔드로 텐서플로만 지원)

텐서플로와 케라스 다음으로 가장 인기 있는 딥러닝 라이브러리는 페이스북 파이토치(Pytorch)입니다.
이 API는 케라스와 매우 비슷합니다.
2.1 텐서플로 2 설치
1. pip 명령으로 텐서플로 설치
2. virtuallenv으로 격리된 환경으로 만들었다면 먼저 이 환경을 활성화하자.
$ cd $ML_PATH #ML을 위한 작업 디렉터리(예를 들면, $HOME/ml)
$ source my_env/bin/activate #리눅스나 맥OS에서
$ .\my_env\Scripts\activate #Windows에서
그다음 텐서플로 2를 설치합니다.(virtuallenv를 사용하지 않는다면 관리자 권한이 필요합니다 (아니면 --user 옵션 추가)
제대로 설치가 되었는지 확인하려면 파이썬 셀(Shell)이나 주피터 노티북을 열어 tf.keras를 임포트하고 버전을 출력해서 확인합니다.
import tensorflow as tf
from tensorflow import keras
tf.__version__
keras.__version__
두 번째 버전이 tf.keras에서 구현된 케라스 API 버전입니다. -tf 접미사는 tf.keras가 텐서플로 특화된 기능이 추가되어 케라스 API를 구현했다는 것을 나타냅니다.
이제 tf.keras를 사용해 이미지 분류기를 만들어봅시다.
2.2 시퀀셜 API를 사용하여 이미지 분류기
먼저 데이터셋을 적재해야 합니다. MNIST를 그대로 대체할 수 있는 패션(Fashion) MNIST를 다루어보겠습니다.
MNIST(10개의 클래스로 이루어진 28x28 픽셀 크기의 흑백 이미지 70,000개)와 형태가 정확히 같지만 손글씨 숫자가 아니라 패션 아이템을 나타내는 이미지입니다.
클래스마다 샘플이 더 다양하므로 MNIST보다 훨씬 어려운 문제입니다.
케라스를 사용하여 데이터셋 적재하기
케라스는 MNIST, 패션 MNIST, 2장에서 사용한 캘리포니아 주택 데이터셋을 포함하여 널리 사용되는 데이터셋을 다운로드하고 적재할 수 있는 유틸리티 함수를 제공합니다. 패션 MNIST 데이터셋을 적재해봅시다.
from tensorflow import keras
fashion_mnist = keras.datasets.fashion_mnist
(X_train_full, y_train_full), (X_test, y_test) = fashion_mnist.load_data()
사이킷런 대신 케라스를 사용하여 MNIST나 패션 MNIST 데이터를 적재할 때 중요한 차이점은 각 이미지가 784 크기의 1D 배열이 아니라 28x28 크기의 배열이라는 것입니다. 또한 픽셀 강도가 실수(0.0에서 255.0까지)로 표현되어 있습니다.
훈련 세트의 크기와 데이터 타입을 확인해봅시다.
>>> X_train_full.shape
(60000, 28, 28)
>>> X_train_full.dytpe
dtype('uint8')
이 데이터셋은 이미 훈련 세트와 테스트 세트로 나누어져 잇습니다. 하지만 검증 세트는 없으므로 여기에서 만들겠습니다.
또한 경사 하강법으로 신경망을 훈련하기 때문에 입력 특성의 스케일을 조정해야 합니다.
간편하게 픽셀 강도를 255.0으로 나누어 0~1 사이 범위로 조정하겠습니다. (자동으로 실수로 변환됩니다)
X_valid, X_train = X_train_full[:5000] / 255.0, X_train_full[5000:] / 255.0
y_valid, y_train = y_train_full[:5000], y_train_full[5000:]
X_test = X_test / 255.0
MNIST의 레이블이 5이면 이 이미지가 손글씨 숫자 5를 나타냅니다.
하지만 패션 MNIST는 레이블에 해당하는 아이템을 나타내기 위해 클래스 이름의 리스트를 만들어야 합니다.
class_names = ["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat",
"Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]
예를 들어 훈련 세트에 있는 첫 번째 이미지는 코트를 나타냅니다.
class_names[y_train[0]]=> 'Coat'
시퀀셜 API를 사용하여 모델 만들기
이제 신경망을 만들어보겠습니다. 다음은 두 개의 은닉층으로 이루어진 분류용 다층 퍼셉트론입니다.
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layers.Dense(300, activation="relu"))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
- 첫번째 라인은 Sequential 모델을 만듭니다. 이 모델은 가장 간단한 케라스의 신경망 모델입니다. 순서대로 연결된 층을 일렬로 쌓아서 구성합니다. 이를 시퀀셜(Sequential) API라고 부른다.
- 그 다음 첫 번째 층을 만들고 모델을 추가합니다. Flatten 층은 입력 이미지를 1D 배열로 변환합니다.
즉, 입력 데이터 X를 받으면 X.reshape(-1, 28*28)을 계산합니다. 이 층은 어떤 모델 파라미터도 가지지 않고 간단한 전처리를 수행할 뿐입니다.
모델의 첫 번째 층이므로 input_shape를 지정해야 합니다. 여기에는 배치 크기를 제외하고 샘플의 크기만 써야 합니다.
또는 첫 번째 층으로 input_shape=[28,28]로 지정된 keras.layers.InputLayer 층을 추가할 수도 있습니다. - 그다음 뉴런 300개를 가진 Dense 은닉층을 추가합니다. 이층은 Relu 활성화 함수를 사용합니다. Dense 층마다 각자 가중치 행렬을 관리합니다. 이 행렬에는 층의 뉴런과 입력 사이의 모든 연결 가중치가 포함됩니다. 또한 (뉴런마다 하나씩 있는) 편향도 벡터도 관리합니다.
- 다음 뉴런 100개를 가진 두 번째 Dense 은닉층을 추가합니다. 역시 ReLU 활성화 함수를 사용합니다.
- 마지막으로 (클래스마다 하나씩) 뉴런 10개를 가진 Dense 출력층을 추가합니다.
(배타적인 클래스이므로) 소프트맥스 활성화 함수를 사용합니다.
* 사실 시퀀셜 API는 첫 번째 층에 지정된 input_shape를 사용해 자동으로 InputLayer 층을 추가해줍니다.
summary() 메서드로 출력한 결과는 이 층이 나타나지 않습니다.
앞에서와 같이 층을 하나씩 추가하지 않고 Sequential 모델을 만들 때 층의 리스트를 전달할 수 있습니다.
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layers.Dense(300, activation="relu"))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
모델의 summary() 메서드는 모델에 있는 모든 층을 출력합니다.
- 각 층의 이름(층을 만들 때 지정하지 않으면 자동으로 생성됩니다),
- 출력 크기(None은 배치 크기에 어떤 값도 가능하다는 의미입니다),
- 파라미터 개수
마지막에 훈련되는 파라미터와 훈련되지 않은 파라미터를 포함하여 전체 파라미터 개수를 출력합니다.
이 예에서는 훈련되는 파라미터만 있습니다.
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
dense_3 (Dense) (None, 300) 235500
dense_4 (Dense) (None, 100) 30100
dense_5 (Dense) (None, 10) 1010
=================================================================
Total params: 266,610
Trainable params: 266,610
Non-trainable params: 0
_________________________________________________________________
Dense 층은 보통 많은 파라미터를 가집니다.
ex. 첫 번째 은닉층은 784x300개의 연결 가중치와 300개의 편향을 가집니다. 이를 더하면 무려 파라미터가 235,500개나 됩니다.
이런 모델은 훈련 데이터를 학습하기 충분한 유연성을 가집니다. ( = 과대적합의 위험을 갖는다)
-> 특히 훈련 데이터가 많지 않을 경우
모델에 있는 층의 리스트를 출력하거나 인덱스로 층을 쉽게 선택할 수 있습니다.
또는 이름으로 층을 선택할 수도 있습니다.
model.layers[<keras.layers.reshaping.flatten.Flatten at 0x22fdaf23be0>, <keras.layers.core.dense.Dense at 0x22fdaf236d0>, <keras.layers.core.dense.Dense at 0x22fe0bbc3d0>, <keras.layers.core.dense.Dense at 0x22fdaf23c70>]
>> hidden1 = model.layers[1]
>> hidden1.name
'dense'
>> model.get_layer('dense') is hidden1
True
층의 모든 파라미터는 get_weights() 메서드와 set_weights() 메서드를 사용해 접근할 수 있습니다.
Dense 층의 경우 연결 가중치와 편향이 모두 포함되어 있습니다.
weights, biases = hidden1.get_weights()
weightsarray([[ 0.01439194, -0.03625511, 0.0155271 , ..., -0.0739205 , -0.06200517, 0.01496566], [ 0.0456809 , 0.06451279, -0.01076042, ..., -0.04655401, 0.0196445 , 0.00607672], [ 0.00865509, -0.05258795, 0.00210793, ..., -0.03593556, 0.05691946, -0.0412996 ], ..., [ 0.01443137, 0.01005859, -0.04633356, ..., -0.01226273, -0.01821947, 0.01598773], [ 0.06625934, -0.04997986, 0.06317751, ..., -0.03549185, 0.04460311, 0.04762685], [-0.0540549 , -0.06883103, -0.02590883, ..., 0.01715077, 0.05982393, 0.02769381]], dtype=float32)
>>weights.shape
(784, 300)
>> biases
>> biases.shape
(300,)
Dense 층은 (앞서 언급한 대칭성을 깨뜨리기 위해) 연결 가중치를 무작위로 초기화합니다.
편향은 0으로 초기화합니다.
다른 초기화 방법을 사용하고 싶다면 층을 만들 때 kernel_initializer(커널(kernel)은 연결 가중치 행렬)와 bias_initializer 매개변수를 설정할 수 있습니다.
가중치 행렬의 크기는 입력의 크기에 달려 있습니다.
=> Sequential 모델에 첫 번째 층을 추가할 때 input_shape 매개변수를 지정한 것입니다.
=> 케라스는 모델을 빌드하기 전까지 입력 크기를 기다릴 것입니다.
=> 모델 빌드는 실제 데이터를 주입할 때나(예를 들면, 훈련 과정 중에) build() 메서드를 호출할 때 일어납니다
=> 모델이 실제 빌드되기 전에 층이 가중치를 가지지 않으면(summary() 메서드 호출이나 모델 저장 등의) 특정 작업을 수행할 수 없습니다
모델 컴파일
모델을 만들고 나서 compile() 메서드를 호출하여 사용할 손실 함수와 옵티마이저(optimizer)를 지정해야 합니다.
model.compile(loss="sparse_categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])- 먼저 레이블이 정수 하나로 이루어져 있고(즉, 샘플마다 타깃 클래스 인덱스 하나가 있습니다. 여기에서는 0에서 9까지 정수)
- 클래스가 배타적이므로 "sparse_categorical_crossentropy" 손실을 사용
- 만약 샘플마다 클래스별 타깃 확률을 가지고 있다면 대신 "categorical_crossentropy" 손실을 사용해야 합니다.
- 이진 분류나 다중 레이블 이진 분류를 수행한다면 출력층에 "softmax" 함수 대신 "sigmoid" 함수를 사용하고 "binary_crossentropy" 손실을 사용한다.
옵티마이저에 "sgd"를 지정하면 기본 확률적 경사 하강법(stochastic gradient descent)을 사용하여 모델을 훈련한다는 의미입니다. 다른 말로 하면 케라스가 앞서 소개한 역전파 알고리즘을 수행합니다. (즉, 후진 모드 자동 미분과 경사 하강법)
* SGD 옵티마이저를 사용할 때 학습률을 튜닝하는 것이 중요합니다. (optimizer="sgd"는 기본값 lr=0.01을 사용)
마지막으로 분류기이므로 훈련과 평가 시에 정확도를 측정하기 위해 "accuracy"로 지정
모델 훈련과 평가
모델을 훈련하려면 간단하게 fit() 메서드를 호출합니다.
history = model.fit(X_train, y_train, epochs=30, validation_data=(X_valid, y_valid))- 입력 특성(X_train)과 타깃 클래스(y_train), 훈련할 에포크 횟수(지정하지 않으면 기본값이 1이라서 좋은 솔루션으로 수렴하기 충분하지 않을 것입니다)를 전달합니다. (검증 세트도 전달)
- 케라스는 에포크가 끝날 때마다 검증 세트를 사용해 손실과 추가적인 측정 지표를 계산합니다. (이 지표는 모델이 얼마나 잘 수행되는지 확인하는데 유용)
- 훈련 세트 성능이 검증 세트보다 월등히 높다면 아마도 모델이 훈련 세트에 과대적합
훈련 에포크마다 케라스는 (진행 표시줄(progress bar)과 함께) 처리한 샘플 개수와 샘플마다 걸린 평균 훈련 시간, 훈련 세트와 검증 세트에 대한 손실과 정확도(또는 추가로 요청한 다른 지표)를 출력합니다.
훈련 정확도와 차이가 크기 없기 때문에 과대적합이 많이 일어나지 않는 것 같습니다.
※ validation_data 매개변수에 검증 세트를 전달하는 대신 케라스가 검증에 사용할 훈련 세트의 비율을 지정할 수 있습니다.
어떤 클래스는 많이 등장하고 다른 클래스는 조금 등장하여 훈련 세트가 편중되어 있다면 fit() 메서드를 호출할 때
class_weight 매개변수를 지정하는 것이 좋습니다.
적게 등장하는 클래스는 높은 가중치를 부여하고 많이 등장하는 클래스는 낮은 가중치를 부여합니다.
케라스가 손실을 계산할 때 이 가중치를 사용합니다.
샘플별로 가중치를 부여하고 싶다면 sample_weight 매개변수를 지정합니다.
(class_weight와 sample_weight가 모두 지정되면 케라스는 두 값을 곱하여 사용합니다).
어떤 샘플은 전문가에 의해 레이블이 할당되고 다른 샘플은 크라우드소싱(crowdsourcing) 플랫폼을 사용해 레이블이 할당되었다면 샘플별 가중치가 도움될 수 있습니다.
validation_data 튜플의 세 번째 원소로 검증 세트에 대한 샘플별 가중치를 지정할 수도 있습니다.
but, 클래스 가중치는 지정 x
fit() 메서드가 반환하는 History 객체에는 훈련 파라미터(history.params), 수행된 에포크 리스트(history.epoch)가 포함됩니다.
이 객체의 가장 중요한 속성은 에포크가 끝날 때마다
- 훈련세트와 검증세트에 대한 손실
- 지표를 담은 딕셔너리
import pandas as pd
import matplotlib as plt
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1) # 수직축의 범위를 [0-1] 사이로 설정정
plt.show()
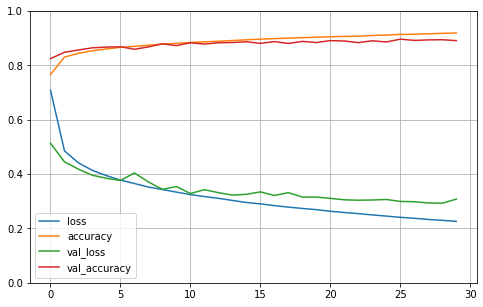
- 훈련하는 동안 훈련 정확도와 검증 정확도가 꾸준히 상승하는 것을 볼 수 있다.
- 훈련 손실과 검증 손실은 감소
- 훈련 초기에 모델이 훈련 세트보다 검증 세트에서 더 좋은 성능을 낸 것처럼 보인다.
- 검증 손실은 에포크가 끝난 후에 계산되고 훈련 손실은 에포크가 진행되는 동안 계산된다.
- 훈련 곡선은 에포크의 절반만큼 왼쪽으로 이동해야 한다.
일반적으로 충분히 오래 훈련하면 훈련 세트의 성능이 검증 세트의 성능을 앞지릅니다.
검증 손실이 여전히 감소한다면 모델이 완전히 수렴되지 않았다.
* 모델 성능에 만족스럽지 않으면 처음으로 되돌아가서 하이퍼파라미터를 튜닝해야 합니다. (학습률)
학습률이 도움이 되지 않으면 다른 옵티마이저를 테스트?
여전히 성능이 높지 않으면 층 개수, 층에 있는 뉴런 개수, 은닉층이 사용하는 활성화 함수와 같은 모델의 하이퍼파라미터를 튜닝하는 것도 좋은 방법입니다. (또한 배치 크기와 같은 다른 하이퍼파라미터를 튜닝)
모델의 검증 정확도가 만족스럽다면 모델을 상용 환경으로 배포하기 전에 테스트 세트로 모델을 평가하여 일반화 오차를 추정
=> evaluate() 메서드 사용
모델을 사용해 예측을 만들기
X_new = X_test[:3]
y_proba = model.predict(X_new)
y_proba.round(2)
=> 각 샘플에 대해 0에서 9까지 클래스마다 각각의 확률을 모델이 추정했습니다.
(실제로는 확률값이 낮더라도) 가장 높은 확률을 가진 클래스에만 관심이 있다면 다음과 같이 활용할 수 있습니다.
import numpy as np
# 예측 확률 계산
predictions = model.predict(X_new)
# 가장 높은 확률을 가진 클래스 선택
predicted_classes = np.argmax(predictions, axis=1)
'딥러닝' 카테고리의 다른 글
| 그레이디언트 소실과 폭주 문제 (1) | 2025.05.07 |
|---|---|
| 신경망 하이퍼파라미터 튜닝하기 (1) | 2025.05.04 |
| 케라스 딥러닝 모델링 A to Z: 설계, 저장, 콜백 활용까지 (0) | 2025.05.03 |
| 다층 퍼셉트론의 이해: 역전파 학습과 실제 활용 (회귀·분류) (1) | 2025.04.29 |
| 케라스를 사용한 인공 신경망 소개 (1) | 2025.04.27 |