이 글은 <핸즈온 머신러닝 2판>을 참고하여 만들어졌습니다.
11.2 사전훈련된 층 재사용하기
일반적으로 아주 큰 DNN을 처음부터 새로 훈련하는 것은 좋은 생각이 아닙니다.
해결하려는 것과 비슷한 유형의 문제를 처리한 신경망이 이미 있는지 찾아본 다음, 그 신경망의 하위층을 재사용하자.
=> 이를 전이 학습(transfer learning)이라고 한다.
이 방식은 훈련 속도를 크게 높일뿐만 아니라 필요한 훈련 데이터도 크게 줄어듭니다.
동물, 식물, 자동차, 생활용품을 포함해 카테고리 100개로 구분된 이미지를 분류하도록 훈련한 DNN이 있다고 가정합시다.
이런 작업들은 비슷한 점이 많고 심지어 일부 겹치기도 하므로 첫 번째 신경망의 일부를 재사용해봐야 합니다.
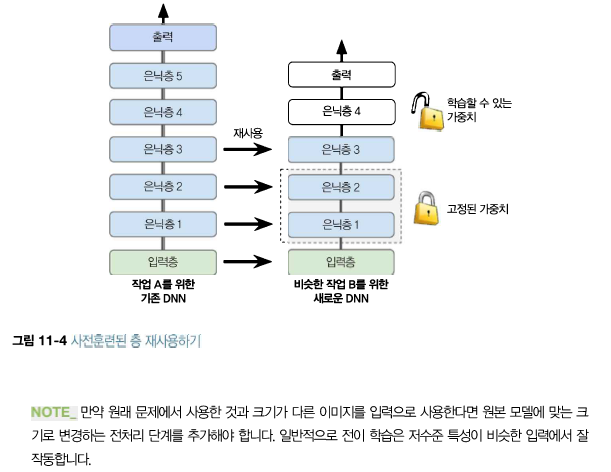
보통 원본 모델의 출력층을 교체.
=> 이 층이 새로운 작업에 가장 유용하지 않는 층이고 새로운 작업에 필요한 출력 개수와 맞지 않을 수도 있습니다.
원본 모델의 상위 은닉층은 하위 은닉층보다 덜 유용합니다.
=> 새로운 작업에 유용한 고수준 특성은 원본 작업에서 유용했던 특성과는 상당히 다르기 때문입니다.
재사용할 층 개수를 잘 선정하는 것이 필요합니다.
Tip) 작업이 비슷할수록 (낮은 층부터 시작해서) 더 많은 층을 재사용하세요 아주 비슷한 작업이라면 모든 은닉층을 유지하고 출력층만 교체합니다.
먼저 재사용하는 층을 모두 동결합니다
(즉, 경사 하강법으로 가중치가 바뀌지 않도록 훈련되지 않는 가중치로 만듭니다).
그다음 모델을 훈련하고 성능을 평가합니다.
맨 위에 있는 한 두개의 은닉층의 동결을 해제하고 역전파를 통해 가중치를 조정하여 성능이 향상되는지 확인합니다.
훈련 데이터가 많을수록 많은 층의 동결을 해제할 수 있습니다.
재사용 층의 동결을 해제할 때는 학습률을 줄이는 것이 좋습니다. => 가중치를 세밀하게 튜닝하는데 도움이 됩니다.
더 좋은 성능을 내기 위해 상위 은닉층들을 제거하고 남은 은닉층을 다시 동결하는것도 좋은 방법이다.
이런 식으로 재사용할 은닉층의 적절한 개수를 찾을 때까지 반복합니다.
훈련 데이터가 아주 많다면 은닉층을 제거하는 대신 다른 것으로 바꾸거나 더 많은 은닉층을 추가한다.
11.2.1 케라스를 사용한 전이 학습
ex. 8개의 클래스만 담겨 있는 패션 MNIST 데이터셋이 있습니다. 이 데이터셋에는 샌들과 셔츠를 제외한 다른 클래스가 있습니다.
누군가 이 데이터의 클래스를 분류하는 작업 A를 해결하는 모델을 만들고 꽤 좋은 성능을 얻었습니다. => '모델 A'
샌들과 셔츠 이미지를 구분하는 작업 B를 해결하기 위해 이진 분류기를 훈련하려 합니다 => 작업 B
모델 B는 꽤 좋은 성능(97.2%의 정확도)
하지만 모델 B는 클래스가 두 개뿐인 매우 쉬운 문제
=> 혹시 전이 학습이 도움이 될까요?
먼저 모델 A를 로드하고 이 모델 층을 기반으로 새로운 모델(model_B_on_A)을 만듭니다. (출력층 제외)
from tensorflow import keras
model_A = keras.models.load_model("my_model_A.h5")
model_B_on_A = keras.models.Sequential(model_A.layers[:1])
model_B_on_A.add(keras.layers.Dense(1, activation="sigmoid"))
model_A와 model_B_on_A는 일부 층을 공유합니다.
model_B_on_A를 훈련할 때 model_A도 영향을 많이 받습니다.
* 원치 않는다면 층을 재사용하기 전에 model_A를 클론(clone)한다.
clone_model() 메서드로 모델 A의 구조를 복제한 후 가중치를 복사합니다
(clone_model() 메서드는 가중치를 복제하지 않습니다)
model_A_clone = keras.models.clone_model(model_A)
model_A_clone.set_weights(model_A.get_weights())
이제 작업 B를 위해 model_B_on_A을 훈련할 수 있습니다.
하지만 새로운 출력층이 랜덤하게 초기화되어 있으므로 큰 오차를 만들 것입니다(처음 몇 번의 에포크 동안)
따라서 큰 오차 그레이디언트가 재사용된 가중치를 망칠 수 있습니다.
=> 처음 몇 번의 에포크 동안 재사용된 층을 동결하고 새로운 층에게 적절한 가중치를 학습할 시간을 주는 것입니다.
이를 위해 모든 층의 trainable 속성을 False로 지정하고 모델을 컴파일함
for layer in model_B_on_A.layers[:-1]:
layer.trainable = False
model_B_on_A.compile(loss="binary_crossentropy", optimizer="sgd", metrics=["accuracy"])
* 층을 동결하거나 동결을 해제한 후 반드시 모델을 컴파일해야 합니다.
이제 몇 번의 에포크 동안 모델을 훈련할 수 있습니다.
그다음 재사용된 층의 동결을 해제하고 (모델을 다시 컴파일해야 합니다) 작업 B에 맞게 재사용된 층을 세밀하게 튜닝하기 위해 훈련을 계속합니다.
=> 일반적으로 재사용된 층의 동결을 해제한 후에 학습률을 낮추는 것이 좋습니다, (재사용된 가중치를 막기 위해)
history = model_B_on_A.fit(X_train_B, y_train_B, epochs=4, validation_data=(X_valid_B, y_valid_B))
for layer in model_B_on_A.layers[:-1]:
layer.trainable = True
optimizer = keras.optimizers.SGD(lr=1e-4) # 기본 학습률은 1e-2
model_B_on_A.compile(loss="binary_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model_B_on_A.fit(X_train_B, y_train_B, epochs=16,
validation_data = (X_valid_B, y_valid_B))
그럼 최종 점수는? 이 모델의 테스트 정확도는 99.25%!!!
전이 학습이 오차율을 2.8%에서 0.7%까지 낮추었습니다
model_B_on_A.evaluate(X_test_B, y_test_B)
사실 높은 성능을 가진 모델을 찾기까지 여러 가지 설정을 시도해보았습니다.
타깃 클래스나 랜덤 초깃값을 바꾸면 성능이 떨어질 것입니다.
현란한 새 기술이 실제로 도움 X.
전이 학습은 작은 완전 연결 네트워크에서는 잘 동작하지 않는다.
아마도 작은 네트워크는 패턴 수를 적게 학습하고 완전 연결 네트워크는 특정 패턴을 학습한다.
전이 학습은 조금 더 일반적인 특성을 (특히 아래쪽 층에서) 감지하는 경향이 있는 심층 합성곱 신경망에서 잘 동작합니다.
11.2.2 비지도 사전훈련
레이블된 훈련 데이터가 많지 않은 복잡한 문제가 있는데, 비슷한 작업에 대해 훈련된 모델을 찾을 수 없다고 가정해봅시다.
비지도 사전훈련(unsupervised pretraining)이라는 개념이 나옵니다.
사실 레이블이 없는 훈련 샘플을 모으는 것은 비용이 적게 들지만 여기에 레이블을 부여하는 것이 비쌉니다.
비지도 사전훈련 순서?
1. 레이블되지 않은 훈련 데이터를 많이 모을 수 있다면 이를 사용하면 오토인코더(autoencoder)나 생성적 적대 신경망과 같은 비지도 학습 모델을 훈련할 수 있습니다.
2. 그다음 오코인코더나 GAN 판별자의 하위층을 재사용하고 그 위에 출력층을 추가할 수 있습니다.
3. 지도 학습으로 최종 네트워크를 세밀하게 튜닝합니다
왜 비지도 사전훈련?
원래는 볼츠만 머신(restricted Boltzmann machine)(RBM)을 사용한 비지도 사전훈련이 표준
=> 그레이디언트 소실 문제가 완화되고 나서야 역전파 알고리즘만을 사용하여 심층 신경망을 훈련하는 것이 일반화
그러나
- 풀어야 할 문제가 복잡
- 재사용할 수 있는 비슷한 모델이 없을 때
- 레이블된 훈련 데이터가 적고 그렇지 않은 데이터가 많을 때
=> 비지도 사전 훈련이 좋은 선택이다
딥러닝 초기에는 탐욕적 층 단위 사전 훈련(greedy layer-wise pretraining)이라는 부르는 기법을 사용했습니다.
=> 많은 모델을 훈련하는 것의 어려움
1. 하나의 층을 가진 비지도 학습 모델을 훈련 (RBM 사용)
2. 이 층을 동결하고 그위에 다른 층을 추가한 다음 모델을 다시 훈련
3. 반복
일반적으로 한 번에 전체 비지도 학습 모델을 훈련하고 RBM 대신 오토 인코더나 GAN을 사용합니다.

=> 비지도 훈련에서는 비지도 학습 기법으로는 레이블이 없는 데이터로 모델을 훈련합니다.
그 다음 지도 학습 기법을 사용하여 데이터에서 최종 학습을 위해 세밀하게 튜닝합니다.
'딥러닝' 카테고리의 다른 글
| 규제 방법 (1) | 2025.05.18 |
|---|---|
| 고속 옵티마이저 (0) | 2025.05.13 |
| 그레이디언트 소실과 폭주 문제 (1) | 2025.05.07 |
| 신경망 하이퍼파라미터 튜닝하기 (1) | 2025.05.04 |
| 케라스 딥러닝 모델링 A to Z: 설계, 저장, 콜백 활용까지 (0) | 2025.05.03 |