이 책은 <컴파일러 입문 >(저자: 오세만)을 참고하여 만들어졌습니다.
4.1 서론
3장에서 다루었던 정규 언어에 관한 이론을 적용하여 이 장에서는 구체적으로 어휘 분석기를 구현하는 방법을 살펴보자
어휘 분석(lexical analysis) : 소스 프로그램을 하나의 긴 문자열로 보고 차례대로 문자를 검조(scanning)하여 문법적으로 의미있는 최소의 단위로 분할해 내는 것을 말하는데 이 문법적인 단위(syntactic entity)를 토큰(token)이라 부른다.
이러한 작업은 컴파일러의 어휘 분석기(lexcial analyzer)에서 처리하는데 어휘 분석기는 간단히 스캐너(scanner)라 부른다.

토큰은 유한 오토마타에 의해 인식될 수 있으며, 토큰의 구조는 프로그래밍 언어 설계자(language designer)나 컴파일러 구현자(compiler implementor)에 의해 결정되는데 대개의 프로그래밍 언어는 다음과 같은 종류의 토큰을 갖는다.
특수 형태(special form)의 토큰은 언어를 정의할 때 언어 설계자가 결정하는 예약어(reserved word)들이다.
- 지정어는 고유한 의미를 갖는 단어로 문법적인 구조를 표현하기 위해 사용된다.
- 연산자 기호는 연산의 의미를 나타내는 기호
- 구분자는 문법 항목을 구별해 주는 기능을 하는 특수 문자이다.
일반 형태(general form)의 토큰은 프로그래머가 프로그램을 작성할 때 사용하는 명칭과 상수들 => 이 구조는 컴파일러 구현자에 의해 결정된다.
- 명칭은 주로 식별하기 위한 이름으로 사용
- 상수는 자료형에 따라 특정한 값을 갖는다.
각 토큰들은 효율적인 처리를 위해서 고유의 내부 번호를 갖는데 이것을 토큰 번호(token number)라 부른다.
그리고 일반 형태의 토큰은 프로그래머가 사용한 값을 갖는데 이 값을 토큰 값(token vlaue)이라 한다.
명칭의 토큰 값은 그 자신의 스트링 값(string value)이며 상수의 토큰 값은 그 자신의 상수 값.
=> 가끔, 상수를 리터럴(literal)이라 부른다.
- 토큰 ---- 문법적으로 의미있는 최소 단위로 문법에서 terminal 심벌임
- 토큰 번호 ---- 토큰을 대표하는 정수 번호
- 토큰 값 ---- 스트링 값이나 수치 값(string value or numberical value). 명칭인 경우에는 명칭의 스트링 값이며 상수인 경우에는 수치 값이다.
토큰 번호는 Mini C에서 정의한 고유 번호로 C언어의 열거형으로 정의되어 있다.
그리고 토큰 값은 일반 형태의 토큰일 때는 자신의 값이 되며, 특수 형태의 토큰은 토큰 값을 갖지 않지만 편의상 0으로 표시.
토큰 a와 b는 명칭으로 토큰 번호는 모두 4이지만 토큰 값으로 구별된다.
어휘 분석기가 구문 분석기에게 넘겨주는 토큰의 정보는 일반적으로 토큰 번호와 토큰 값의 순서쌍으로 구성된다.
예를 들어, 어휘 분석기는 다음과 같이 입력을 읽어서 그에 해당하는 (토큰 번호, 토큰 값)의 형태로 만들어 차례로 구문 분석기에게 전달한다.
프로그래머가 사용한 명칭에 대한 토큰은 토큰 값은 물론이고 그 속성을 나타내는 정보를 심벌 테이블(symbol table)에 보관하여 의미 분석과 코드 생성 과정에서 중요하게 이용되는데, 이와 같은 심벌 테이블 운영(symbol table management)은 어휘 분석 과정이나, 구문 분석 과정, 또는 의미 분석 과정에서 행해진다.
어휘 분석과정에서 심벌 테이블을 운영하는 경우에 다음과 같이 처리한다.
새로운 명칭의 토큰을 인식하면 심벌 테이블에 명칭을 삽입하고 구문 분석기에는 명칭에 대한 토큰 값으로 스트링 값이 아닌 심벌 테이블의 인덱스(index)를 전달한다.
=> 구문 분석기가 심벌 테이블을 검색하는데 시간을 줄여줌
만약 어휘 분석 과정에서 심벌 테이블을 운영하지 않으면 이와 같은 모든 일을 구문 분석기나 의미 분석기나 해야 할 것이다.
이 이외에도 어휘 분석기는 소스 프로그램의 줄 번호를 기억하여 필요할 때 소스 프로그램을 줄 별로 출력할 수 있게 해준다.
또한 소스 프로그램의 불필요한 공백과 주석(comment)을 모두 처리하는 일을 한다.
컴파일러의 다음 단계인 구문 분석기와의 관계는 다음과 같다. 스캐너는 파서가 토큰이 필요할 때 호출하는 서브루틴이다.
4.2 토큰 인식
어휘 분석기의 설계에 앞서 프로그래밍 언어의 각 토큰의 구조를 기술할 때 이용되는 방법인 정규 표현(regular expression)을 알고 있어야 하며, 필요한 모든 토큰들의 구조를 결정한 후 소스 프로그램 속에서 이것들을 식별해 내기 위한 인식기가 필요한데, 인식기를 설계하는데 편리한 방법인 상태 전이도(transition diagram)와 유한 오토마타(finite automata)를 정규 표현으로부터 얻는 것을 잘 이해하고 있어야 한다.
상태 전이도는 유한 오토마타를 그림으로 표현하는 흐름도(flow graph)로 어떤 모양의 토큰을 인식할 수 있는지를 쉽게 파악할 수 있는 그림이다.
상태 전이도의 각 노드는 상태를 표시하고, 문자를 레이블로 갖는 지시선은 한 상태로부터 소스 프로그램 속의 그 문자를 읽고 다음 상태로의 이동을 나타내며, 이중 원으로 표시된 노드는 한 토큰의 인식을 의미하는 종결 상태를 나타낸다.
이제부터 각 토큰의 종류를 인식하는 인식기를 구성하려 하는데, 다음과 같이 분류하였다.
앞으로 편의상 letter는 l로, digit는 d로 나타내기로 하자.
4.2.1 명칭의 인식
일반적으로 C 언어에서 명칭의 구조는 먼저 문자나 _(underscore)가 나오고 그 다음에 문자나 숫자 또는 _가 반복되는 형태이다.
다음은 이와 같은 형태의 명칭을 인식하는 상태 전이도이며 길이에 관계없이 인식한다.
처음에 상태 S에서 출발하여 letter나 _를 보고 A 상태로 가며 다음 문자를 읽고 letter나 digit 또는 _이면 다시 A 상태가 된다.
이것을 반복하다 letter나 digit 또는 _가 아닌 문자가 나오면 명칭으로 인식하게 된다.
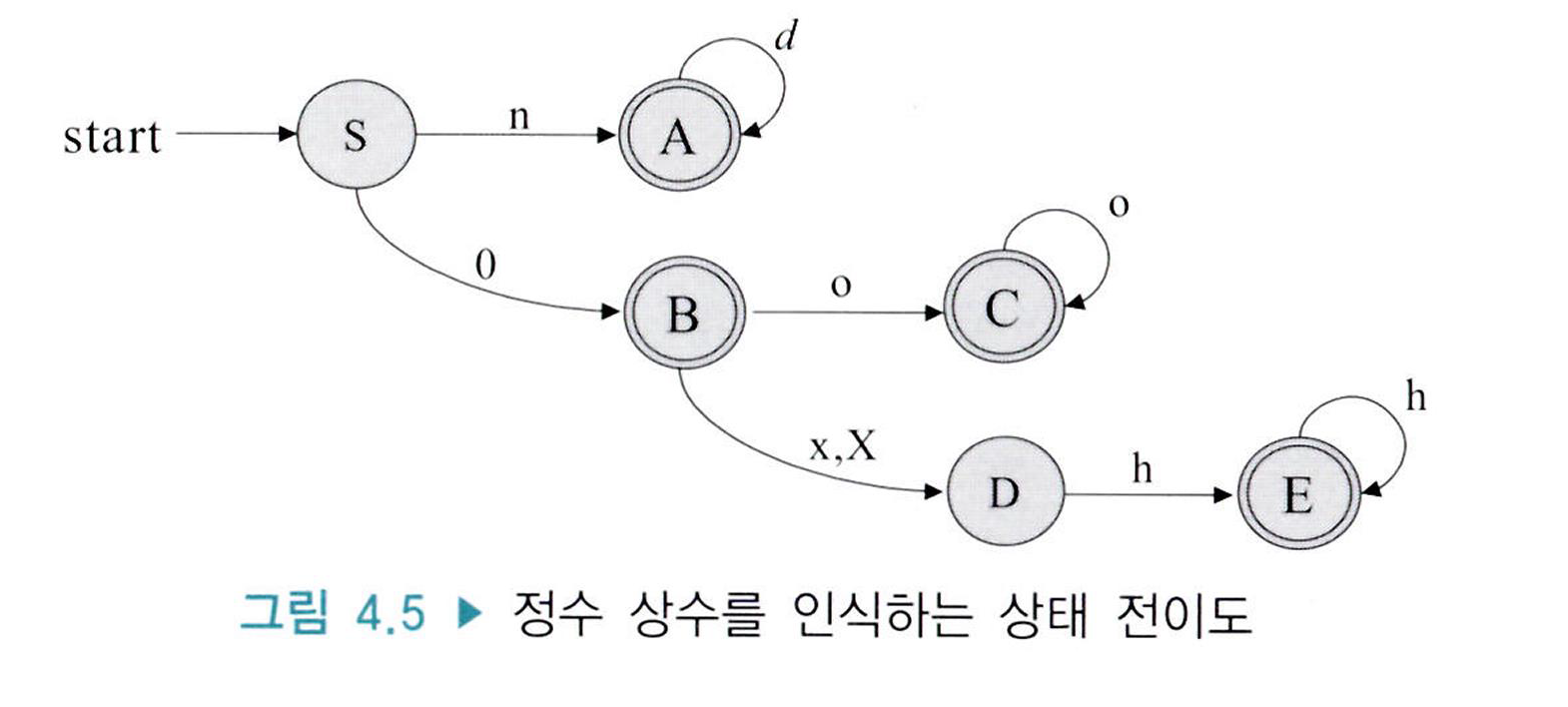
4.2.2 정수 상수의 인식
C언어에서 정수 상수의 종류는 10진수, 8진수, 16진수로 구분된다.
10진수는 0이 아닌 수로 시작하며 8진수는 0으로 시작하고 16진수는 0x 또는 0X로 시작한다.
다음은 C언어에서 허용하는 정수 상수를 인식하는 상태 전이도이다.
여기서 non-zero digit을 n, octal digit을 o, 그리고 hexa digit을 h로 표기하였다.
C언어에서 허용하는 정수 상수를 처리하는 작업을 C언어의 함수로 작성한 것이다.
일반적으로, 스캐너에서 많이 활용되는 함수이다. => p139참고
4.2.3 실수 상수의 인식
실수의 형태는 지수(exponent)부분의 유무에 따라 고정소수점 수(fixed-point number)와 부동소수점 수(float-point number)로 구분된다.
실수를 인식하는 상태 전이도이다.
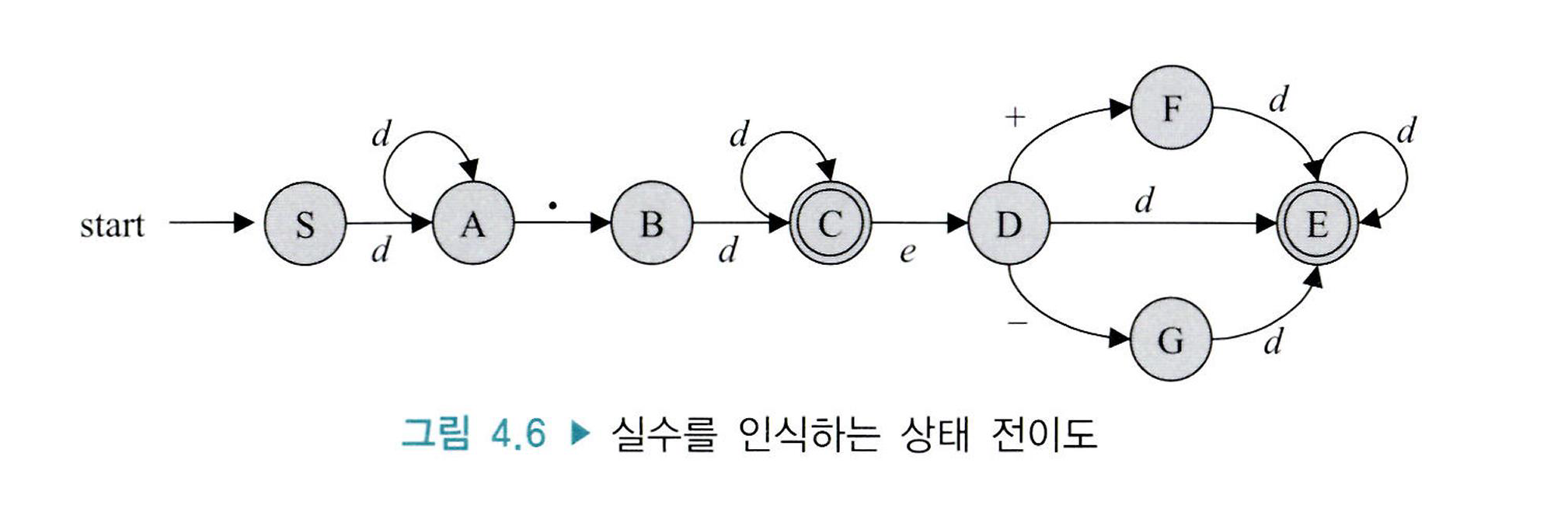
실수 상수의 정규 표현에서 확인할 수 있듯이, 실수의 형태는 지수 부분이 없는 구조와 지수 부분이 존재하는 구조로 되어 있다.
4.2.4 스트링 상수의 인식
일반적으로 스트링 상수(string constant)는 일련의 문자를 "(double quote)와" 사이에 나타낸다.
특히 "를 스트링 상수 안에 넣기 위해서는 에스케이프 문자열을 사용한다.
이와 같은 방법은 C언어에서 사용하는 스트링 상수의 표기법이다.

4.2.5 주석의 처리
모든 프로그래밍 언어는 프로그램의 설명을 위해 주석(comment)을 쓸 수 있는 기능을 갖추고 있다.
보통 주석은 각 프로그래밍 언어에 따라 그 표현 방법이 다르지만 이 책에서는 /*와 */ 사이에 표현한다고 가정하여 이를 인식하는 오토마타와 정규 문법, 정규 표현을 고려해보자.

여기서 a는 * 이외의 문자, b는 *,/ 이외의 문자를 나타낸다.
즉, a = char_set - {*} 그리고 b = char_set -{*, /}이다.
1. 시작 상태 S에서 /*를 만나면 A 상태를 거쳐 상태 B로 이동하고 이 상태에서 주석의 내용을 처리하게 된다.
2. 그리고 *를 만나면 C 상태로 이동하고 이 상태에서 입력이 /이면 주석의 끝이고 *이면 같은 상태를 유지한다.
3. 상태 C에서 *,/ 이외의 문자를 만나면 다시 B 상태로 돌아와 계속 주석의 내용을 처리한다.
정규 표현에서 알 수 있듯이 주석의 형태는 /*와 */ 사잉에 표현되며 주석의 내용은 */를 포함할 수 없다.
마지막으로, /*를 주석의 시작으로 인식한 후, */를 처리하는 프로그램은 아래와 같다.
즉, 일련의 입력 스트림에서 */를 인식하는 프로그램이다.

이제까지 고려한 주석 형태를 보통 텍스트 주석(text comment)이라 부르며
여러 라인의 주석을 기술할 때 사용한다.
한 라인의 주석을 위해서는 보통 라인 주석(line comment)을 사용하며 그 형태는 보통 //로 시작해서 라인 끝까지를 주석으로 간주한다.
컴파일러를 위한 어휘 분석기는 주어진 입력을 선형 시간(linear time) 내에 처리해야 하기 때문에 반드시 결정적 유한 오토마타로 구현해야 한다.
따라서 정규 표현으로 기술된 토큰을 인식하는 어휘 분석기를 구현하는 방법은 다음과 같다.
1. 정규 표현으로부터 비결정적 유한 오토마타를 구성하고 결정적 유한 오토마타로 변환한다.
2. 상태수가 최소화된 결정적 유한 오토마타를 얻어 프로그래밍하면 어휘 분석기를 구현할 수 있다.
4.3 어휘 분석기의 구현
어휘 분석기를 구현하기 위해서는 먼저 문법 표현(grammar description)으로부터 terminal 심벌들의 형태인 토큰의 구조를 결정한다.
- PGS(Parser Generating System)가 문법 표현으로부터 terminal 심벌을 가려내 주고 그 내부 번호를 지정해 준다.
- 이 내부 번호가 토큰 번호이며 파싱 테이블과 밀접한 관계를 갖고 있다.
- 일단 토큰이 결정되면 이 토큰들을 인식할 수 있는 프로그램을 작성해야 한다.
이와 같은 인식 프로그램을 작성하는 방법은 크게 2가지로 나눌 수 있다.
범용 프로그래밍 언어를 사용하여 작성하거나 또는 어휘 분석기 생성기로부터 얻을 수 있다.
먼저, 어휘 분석기를 범용 프로그래밍 언어로 구현하기 위해서는 먼저 토큰들을 인식하기 위한 유한 오토마타를 상태 전이도로 나타내고 그 상태 전이도로부터 실제의 프로그래밍 언어로 각 상태에 대한 프로그램을 작성하면 된다.
앞 절에서 토큰 종류에 따라 실제로 Mini C 언어에 대한 어휘 분석기를 구현해보자.
Mini C의 토큰을 구성하고 있는 특수 심벌(special symbol)과 단어 심벌(word symobl)들은 다음과 같다

위 토큰들을 인식하는 Mini C의 전체적인 상태 전이도는 다음과 같다.

위의 상태 전이도에서, 상태 1이 시작 상태이며 공백 문자(blank)가 나오면 계속해서 같은 상태를 반복한다.
1. 그러다가 letter나 _가 나오면 상태 2번으로 이동하고 여기가 명칭이나 지정어를 인식하는 상태이다.
2. 지정어도 명칭의 형태와 유사하기 때문에, 검조된 문자열을 가지고 지정어 테이블(keyword table)을 검색하여 그곳에서 일치하는 지정어를 발견하면 그 문자열을 지정어로 간주하고 그렇지 않을 경우 명칭으로 인식한다.
3. 상태 5부터 9까지 Mini C에서 허용하는 정수 상수를 인식하는 상태들이며 상태 10은 주석을 처리하는 부분으로 여기서 */를 인식하면 시작 상태인 상태 1로 돌아가서 다시 다른 토큰을 처리하게 된다. 또한 상태 14가 라인 주석을 처리하는 부분이다.

정의된 Mini C에 대한 상태 전이도에 따라 어휘 분석기를 C 프로그램으로 작성하면 아래와 같다.
함수 scanner가 입력 소스에서 한 개의 토큰을 분할해서 복귀하는 루틴이다.
그리고 토큰을 인식할 때 읽어 들인 문자가 더 이상 토큰에 속하지 않는 경우에, 이 문자는 다음 번의 토큰을 인식할 때 다시 처리해야되므로 입력으로 되돌려 져야 한다.
이와 같은 과정을 retract라 부르며 C 언어에서는 함수 ungetc()가 그와 같은 기능을 한다.
=> 책 p150 참조
4.4. 렉스
렉스(Lex)는 1957년 레스크에 의해 발표된 어휘 분석기 생성기이다.
1. 이것은 입력 스트림(input stream)에서 정규 표현으로 기술된 토큰들을 찾아내는 프로그램을 작성하는데 유용한 도구이다.
2. 렉스의 기능은 사용자가 정의한 정규 표현과 액션 코드(action code)를 입력으로 받아 C언어로 쓰여진 프로그램을 출력한다.
3. 이 프로그램은 입력 스트림에서 정규 표현에 해당하는 토큰을 찾았을 때 그와 결합된 액션 코드를 실행한다.

렉스 사용자는 렉스 입력 형식에 따라 필요한 토큰의 구조를 기술하고 그에 따른 액션만 C언어로 작성하면 스캐너 프로그램을 얻을 수 있다.
4.4.1 렉스의 입력
렉스의 입력을 렉스 소스(lex source)라 부르며, 다음과 같이 세 부분으로 구성되어 있다.
<정의 부분>
%%
<규칙 부분>
%%
<사용자 부프로그램 부분>
여기서, %%가 각 부분을 구분하는 구분자이며 각 부분은 반드시 순서적으로 기술되어야 한다.
먼저, <정의 부분>은 다음과 같은 형태로 구성된다.

여기서 %{와 %} 사이에는 액션 코드를 C언어로 작성할 때 필요한 자료 구조, 변수, 그리고 상수 등을 선언할 수 있는 부분이다.
1. 렉스는 %{와 %} 사이에 있는 C 프로그램 부분을 렉스의 출력인 lex.yy.c의 앞부분에 그대로 복사한다.
2. 이름 정의 부분은 특정한 정규 표현을 하나의 이름으로 정의하여 그 형태의 정규 표현이 필요할 때마다 쓸 수 있도록 해주는 부분이다.
=> 이는 정규 표현에 대한 매크로 정의로 간주할 수 있다.
3. 이름은 최소한 한 개 이상의 문자로 구성되며 <규칙 부분>에서 사용할 때는 {과 } 사이에 쓴다.
4. 치환식은 이름에 해당하는 정규표현이며 이름과 치환식 사이에는 적어도 하나의 공백 또는 탭(tab) 문자로 분리되어야 한다.
<규칙 부분>은 렉스 입력의 핵심 부분으로 토큰의 형태를 표현하는 정규 표현과 그 토큰이 인식되었을 때 처리할 행위를 기술하기 위한 부분인 액션 코드로 구성된다. (Rules :: = regular expressions + actions).
여기서, %%는 <정의 부분>과 구분을 나타내는 구분자이며, Ri는 정규 표현이고, Ai는 액션 코드로 입력 스트림에서 일치되는 Ri를 찾앗을 때, 어휘 분석기가 해야할 행동을 기술하는 액션 코드로 C 프로그램으로 작성된다.
<규칙 부분>의 간단한 예 + 의미
(1) int printf("found keyword int\n");
: 이는 입력 스트림 내에서 문자열 int를 매칭했을 때 "found keyword int"라는 메시지를 출력하라는 의미를 나타낸다.
(2) [0-9]+ { nc++; printf("found a integer constant\n");}
: 숫자로 이루어진 문자열과 매칭되며, 이때 액션은 nc를 하나 증가하고 메시지를 출력하는 것이다. 이와 같이 액션 코드가 2개이상의
문장으로 이루어지면 반드시 C언어의 복합문(compound statement)으로 작성해야 한다.
렉스 입력의 세 번째 부분인 <사용자 부프로그램 부분>은 렉스의 입력을 작성할 때 사용되는 부프로그램들을 정의하는 곳으로 렉스에 의한 어떤 처리 없이 그대로 렉스의 출력인 lex.yy.c에 복사된다.
4.4.2 렉스의 정규 표현
형식 언어 이론에서 정의한 정규 표현을 바탕으로 실제로 렉스에서 제공된 방법을 사용하여 토큰의 형태를 정형하게 표현할 수 있어야 한다.
렉스의 정규 표현은 크게 텍스트 문자(text character)와 연산자 문자(operator character)들로 구성된다.
Lex regular expression ::= text characters + operator characters
텍스트 문자는 입력 스트림에서 실제로 매칭되는 부분이고 연산자 문자는 반복 또는 선택 등을 나타내는 특수 문자들이다.
렉스에서 토큰의 구조를 쉽게 표현할 수 있도록 제공한 연산자 문자들은 다음과 같으며 그 의미를 살펴보자.
"\[ ] ^ - ? . * + | ( ) $ / { } % < >
(1) " : " 사이에 있는 모든 문자는 텍스트 문자로 취급된다.
(2) \ : 한 개의 문자를 에스케이프하기 위하여 사용된다. 즉, 한 개의 문자를 텍스트 문자로 취급하고자 하는 경우 특수 문자 앞에 덧붙임으로서 해결할 수 있다.
(3)[] : 문자들의 종류를 정의하는데 사용한다. 예를 들어, [abc]는 a,b,c 중에서 한 문자를 나타낸다.
[] 내에 사용된 대부분의 연산자 문자는 의미를 상실한다. -, ^, \ 만이 특수한 의미를 갖는다.
- -는 범위를 표시한다.
- ^은 여집합(complement)을 표현한다.
- \는 C언어의 에스케이프 문자열로 간주된다.
(4) * : 0번 이상 반복을 나타낸다. 즉, a*는 a가 0번 이상 반복될 수 있음을 나타낸다.
(5) + : 한 번 이상 반복될 수 있음을 나타낸다.
(6) ? : 선택을 의미하는 연산자로서 ab?c는 b가 선택적이므로 abc 또는 ac를 의미한다.
(7) | : 택일을 위한 연산자.
(8) ^ : 라인의 시작에서만 인식된다. ^(hat)의 의미와 문자 클래스 연산자 [] 내에서 ^의 의미인 여집합과는 구별해야 한다.
(9) $ : 오직 라인의 끝에서만 인식
(10) / : 접미 문맥(trailing context)을 명시할 때 사용
(11) . : 점(dot)은 개행 문자를 제외한 모든 문자들을 나타낸다.
(12) {} : 정의된 이름을 치환식으로 확장할 때 사용한다.
4.4.3 렉스의 액션 코드
액션 코드(action code) 부분은 정규 표현에 일치되는 문자열,
=> 즉 토큰이 인식되었을 때 실행해야 할 행동을 C언어로 기술하는 부분이다.
인식되지 않은 모든 문자에 대해 실행되는 디폴트(default) 행위는 입력을 출력으로 그대로 복사하는 것이다.
따라서 그대로 통과되는 문자열이 없이 모든 입력을 처리하고자 하는 렉스 사용자는 모든 문자열을 처리할 수 있도록 렉스의 <규칙부분>을 작성하여야 한다. => 표준 입력 : stdin 출력: stdout
어떤 행위도 실행할 필요가 없는 문자열에 대한 처리는 다음과 같이 C언어의 널 문장(null statement)을 사용한다.
=> 이것은 구분자로 사용된 공백, 탭, 개행 문자를 입력에서 무시하고자 할 경우에 처리하는 방법이다.
- 동일한 액션 코드의 반복적인 표기를 생략하기 위한 방법은 |를 사용함으로서 해결할 수 있다.
- 렉스의 전역 변수(global variable)인 yytext는 문자 배열형(character array type)으로 어떤 정규 표현에 의해 실제로 매칭된 문자열 값을 갖고 있다.
- 따라서 토큰 값이 필요한 경우에 yytext의 내용을 사용하여 해결할 수 있다.
1. 전역 변수:
- yytext: 입력 스트림에서 정규 표현하고 매칭된 실제 문자열
- yyleng: 매칭된 문자열의 길이를 나타내는 변수
2. 함수:
- yymore() : 현재 매칭된 문자열의 끝에 다음에 인식될 문자열이 덧붙여지도록 하는 함수. 이 모든 문자열은 yytext에 저장
- yyless(n) : n개의 문자만을 yytext에 남겨두고 나머지는 다시 처리하기 위하여 입력 스트림으로 되돌려 보내는 함수
- yywrap() : 렉스가 입력 스트림의 끝을 만났을 때 호출하는 함수. 정상적인 경우에 이 함수의 복귀 값은 1이 된다.
3. 입출력 함수:
- input() : 입력 스트림으로부터 다음 문자를 읽는 함수
- output() : 출력 스트림으로 문자 c를 내보내는 함수
- unput(c) : 다시 처리될 수 있도록 문자 c를 입력 스트림으로 되돌려 보내는 기능을 하는 함수
4.4.4 스캐너의 생성 및 동작
렉스를 이용하여 스캐너를 생성하는 과정을 나타내면 다음과 같다.
필요한 작업을 처리할 수 있도록 렉스 입력을 작성한 뒤, 렉스를 통하여 lex.yy.c를 생성한다.
생성된 lex.yy.c 파일을 컴파일하면 필요한 스캐너를 얻을 수 있다.

일반적으로 렉스 입력을 기술한 렉스 파일의 확장자(extension name)는 *.I이며, UNIX에서 렉스의 실행 방법은 명령어 lex를 사용한다.
여기서 MiniC.1이 렉스의 입력 파일이다. ($ lex MiniC.1)
=> 이 결과 C 언어로 된 파일 lex.yy.c를 출력 => 이 파일을 컴파일하여 실행시키면 필요한 스캐너가 된다.
$ cc lex.yy.c -o MiniC -11
$ MiniC < perfect.me
여기서 -11은 렉스의 디폴트 라이브러리를 링크시키기 위한 것이다.
렉스의 출력은 C 프로그램의 lex.yy.c이다.
- 이 파일 내에는 스캐너 역할을 담당하는 yylex()가 포함되어 있다.
- yylex()는 렉스의 입력에서 명시한 정규 표현과 일치하는 토큰을 입력 스트림에서 찾을 때까지 한 번에 한 문자씩 계속 읽어들인다.
- 토큰이 매칭되면 해당 정규 표현과 결합된 액션 코드가 실행되며 함수 yylex()의 복귀 값(return value)이 바로 토큰 번호에 해당한다.
- 또한 yylex()를 호출한 함수가 토큰 값을 요구하는 경우 외부 변수 yytext의 내용을 복사하여 필요로 하는 함수로 전달하게 된다.
- 함수 yylex()는 입력 파일의 끝(end-of-file)에 도착할 때까지 토큰을 생성한다.
- 파일의 끝에 도달하면 yylex()는 함수 yywrap()을 호출한 후 0을 복귀한다.
- 그러므로 모든 토큰을 다 처리한 후, 수행할 일이 더 존재하는 경우 yywrap() 내에서 처리하면 된다.
렉스의 선택 규칙은 다음과 같다.
1. 토큰을 가장 길게 인식할 수 있는 정규 표현을 선택한다
2. 인식할 수 있는 토큰의 길이가 같은 경우, 먼저 기술된 정규 표현을 선택한다.
예를 들어 다음과 같은 렉스 정규 표현을 고려해 보자.

입력 스트림 내에 integers가 있는 경우, 정규 표현[a-z]+로는 여덟 개가 인식되나 정규 표현 integer로는 일곱 개만이 인식되기 때문에
=> 선택 규칙 1에 의해 두 번째 정규 표현에 매칭되어 integers가 인식되며 그에 따른 액션 코드가 실행
그러나 입력이 integers인 경우 정규 표현 integer나 [a-z]+로 인식되는 문자의 개수는 모두 일곱 개로 동일하다.
=> 이러한 경우 규칙 2에 의해 먼저 기술된 정규 표현인 integer에 의해 인식되어 "Keyword intger"란 메시지를 출력하게 된다.
렉스의 출력인 lex.yy.c 프로그램을 렉스 소스와 함께 비교/분석하면 렉스 소스를 구성하고 있는 각 부분을 더 잘 이해할 수 있을 것이다.
'컴파일러' 카테고리의 다른 글
| 구문 분석 (1) | 2025.06.05 |
|---|---|
| Context-free 문법 (1) | 2025.06.04 |
| 정규언어(후반부) (0) | 2025.06.03 |
| 컴파일러의 기초: 형식 언어와 문법 파헤치기 💻 (0) | 2025.04.15 |
| 👨💻 컴파일러란 무엇인가? - (5) | 2025.04.14 |